
Dataflow is a powerful ETL tool that allows transform and enhance data. Dataflow is fully managed, server less service that can autosalce when more computation power needed. Dataflow runs on an open-source Apache Beam SDK and supports SQL, Java and Python APIs. Dataflow can handle streaming and batching processing. Pipeline log monitoring is achieved via Cloud Logging.
This manual will demonstrate how to deploy a streaming pipeline using Pub/Sub and Dataflow. We would need to create a data source that generates fake massages and we publish this messages continuously into Pub/Sub. Next, we will create a streaming Dataflow pipeline that consumes the messages and convert them into an object that BigQuery understands and then check the message again known stop words.
First thing we need to make sure that BigQuery and Dataflow APIs are enabled. Go to APIs & Services and click Enable APIs and Services and search for BigQuery API and Dataflow API.
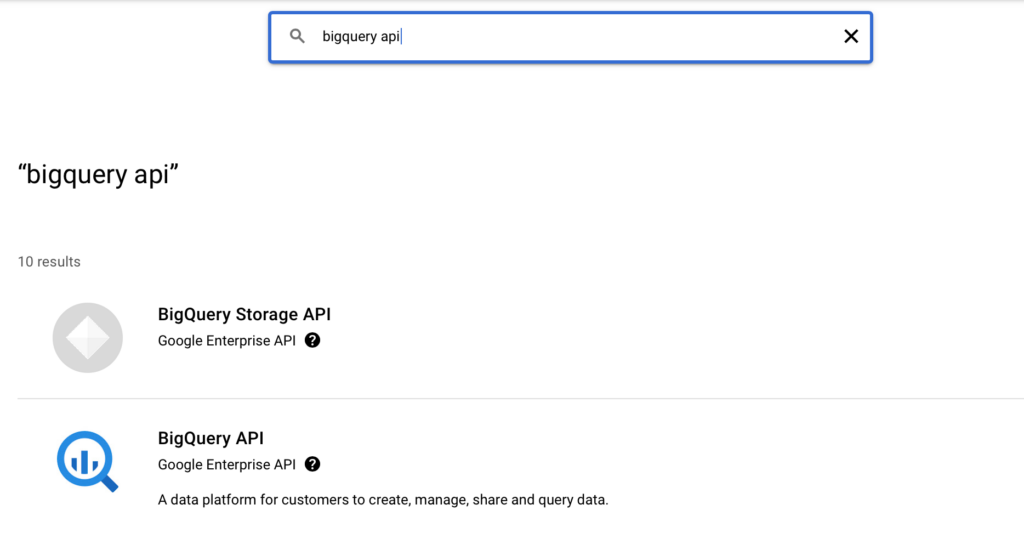
Next, create a new bucket that we will using for this project or you can use any existing buckets. Make a not of the bucket, in my case it is new_bucket_dataflow_project_2021
Next, let’s create our Pub/Sub topic, you can name this topic whatever you want. Remember when you create a new topic Pub/Sub will create a new subscription topic as well, so you can use it or create a new subscription topic. Use default parameters for the new subscription topic.
Now, let’s create a table in BigQuery where all messages we generate will be stored. Go to BigQuery and create new database and table. For the table provide the following schema as text. created_at:TIMESTAMP,tweep_id:STRING,text:STRING,user:STRING,flagged:BOOLEAN
Now, we can start creating a script that will generate stream of data. You can use Cloud Shell or any other code editor. First, we will create a directory for our code and a runtime environment using virtualenv. Virtualenv will keep an isolated Python runtime and mange the libraries we need, so we can keep this separate from any other code that we are using. Use the following commands to create new virtual environment.
virtualenv <new env name>
cd <new env name>
source bin/activate
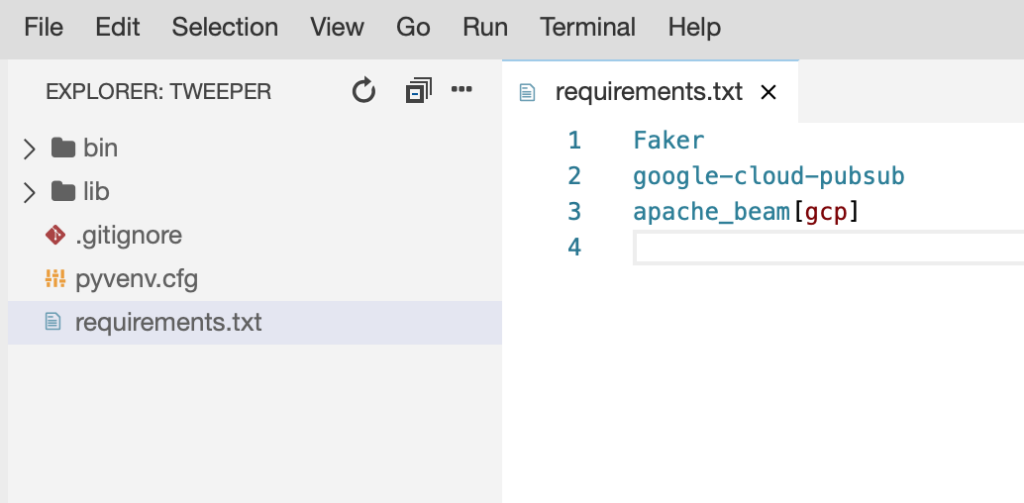
Next, let’s create a requirements.txt, we would need Faker library to create fake data, google-cloud-pubsub library and GCP version of Apache Beam. Don’t forget to save this file.
Now we can install these libraries with pip install -r requirements.txt. Next, we need to create tow Python scripts, one that will create fake social medial messages and the other one that will run our Dataflow pipeline. Create a new python file in you work directory and paste this code, don’t forget to change you project ID and topic.
from faker import Faker
from google.cloud import pubsub_v1
import random
import json
import datetime
import time
PROJECT_ID = '<YOUR_PROJECT_ID>'
TOPIC = '<YOUR_TOPIC>'
usernames = []
faker = Faker()
publisher = pubsub_v1.PublisherClient()
topic_path = publisher.topic_path(PROJECT_ID, TOPIC)
def publish(publisher, topic, message):
data = message.encode('utf-8')
return publisher.publish(topic_path, data=data)
def generate_tweep():
data = {}
data['created_at'] = datetime.datetime.now().strftime('%d/%b/%Y:%H:%M:%S')
data['tweep_id'] = faker.uuid4()
data['text'] = faker.sentence()
data['user'] = random.choice(usernames)
return json.dumps(data)
if __name__ == '__main__':
for i in range(200):
newprofile = faker.simple_profile()
usernames.append(newprofile['username'])
print("Hit CTRL-C to stop Tweeping!")
while True:
publish(publisher, topic_path, generate_tweep())
time.sleep(0.5)Now create another python file and copy/paste this code, again to forget replace your project ID and you subscription topic.
from apache_beam.options.pipeline_options import PipelineOptions
from sys import argv
import apache_beam as beam
import argparse
PROJECT_ID = '<YOUR_PROJECT_ID>'
SUBSCRIPTION = 'projects/' + PROJECT_ID + '/subscriptions/<YOUR SUBSCRIPTION TOPIC>'
SCHEMA = 'created_at:TIMESTAMP,tweep_id:STRING,text:STRING,user:STRING,flagged:BOOLEAN'
# converting JSON into python dictionary object
# Apache Beam supports writing Python dictionaries directly to BigQuery
def parse_pubsub(data):
import json
return json.loads(data)
# changing data format into appropriate date format acceptable by BigQuery
def fix_timestamp(data):
import datetime
d = datetime.datetime.strptime(data['created_at'], "%d/%b/%Y:%H:%M:%S")
data['created_at'] = d.strftime("%Y-%m-%d %H:%M:%S")
return data
# checking message for stop words
# if spotted one the flagged will be changed to True
def check_tweep(data):
BAD_WORDS = ['attack', 'drug', 'gun']
data['flagged'] = False
for word in BAD_WORDS:
if word in data['text']:
data['flagged'] = True
return data
if __name__ == '__main__':
# command line arguments that will be invoked and needed
# to read some extra options that are required when running
# the pipeline on the Dataflow service
parser = argparse.ArgumentParser()
known_args = parser.parse_known_args(argv)
p = beam.Pipeline(options=PipelineOptions())
# creating pipeline
(p | 'ReadData' >> beam.io.ReadFromPubSub(subscription=SUBSCRIPTION).with_output_types(bytes)
| 'Decode' >> beam.Map(lambda x: x.decode('utf-8'))
| 'PubSubToJSON' >> beam.Map(parse_pubsub)
| 'FixTimestamp' >> beam.Map(fix_timestamp)
| 'CheckTweep' >> beam.Map(check_tweep)
| 'WriteToBigQuery' >> beam.io.WriteToBigQuery(
'{0}:tweeper.tweeps'.format(PROJECT_ID),
schema=SCHEMA,
write_disposition=beam.io.BigQueryDisposition.WRITE_APPEND))
result = p.run()
result.wait_until_finish()
This script will create a pipeline with defined each step. First, we use read from Pub/Sub to gram message from our Pub/Sub subscription. Then we decode the incoming message and use our pass Pub/Sub function to turn JSON into a python dictionary. Then, we run the fixed timestamp function and finally, the check tweep function. Once all of those thing are done, we write the output to BigQuery.
When we run this script in Dataflow, the Dataflow service will take continuous batches of messages and push them into BigQuery, distribution the work required to do this amongst its workers. Note that we are applying our functions to the pipeline using beam.Map which the most simple approach. We could alternatively use ParDo to start parallel processing of elements in each P-Collection.
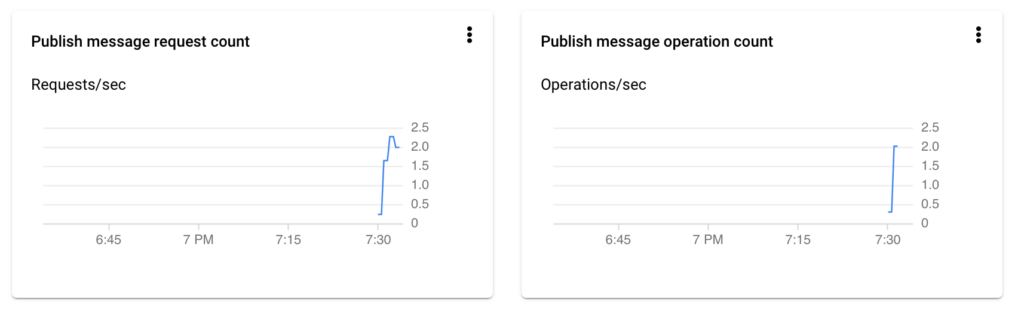
Now we can deploy our pipeline, first we start our first python script that will send messages to put Pub/sub topic. We can check statistics by opening Pub/Sub topics.
Now, we can run our second script and deploy our pipeline. Run the following command
python <script_name.py> --streaming --runner DataflowRunner --project <you-rpoject-id> --temp_location gs://new_bucket_dataflow_project_2021/temp --staging_location gs://new_bucket_dataflow_project_2021/staging --region <your-region> --job_name <job_name>The job was submitted in Dataflow and we can go to console and search for Dataflow service, and click the job you just submitted and will see the visualization of our pipeline and all of the stages we defined previously.
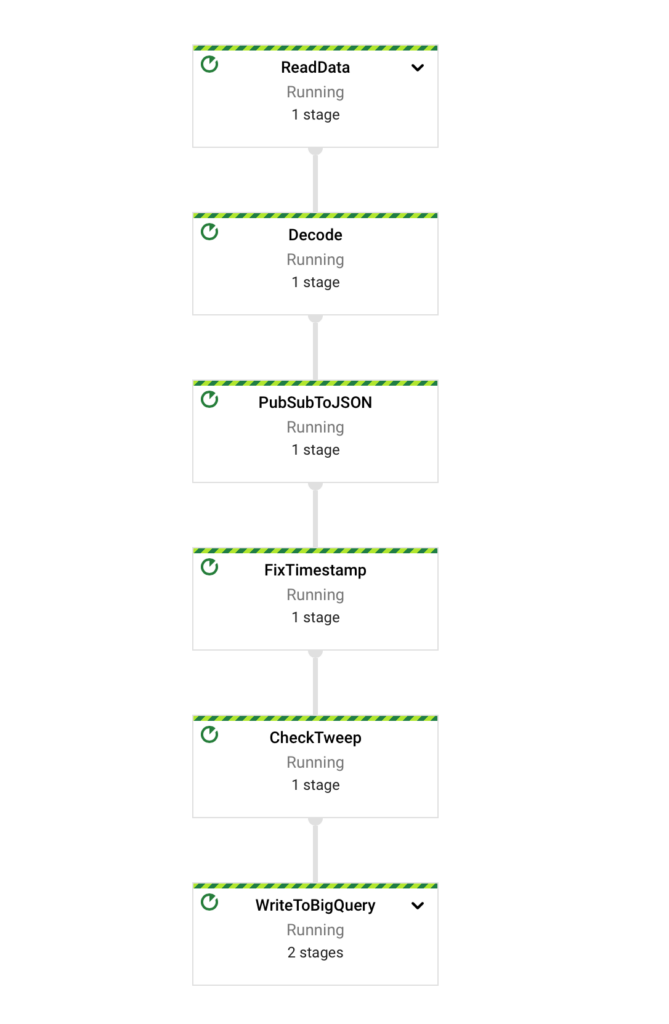
Now we can go to BigQuery and check the table we created before, we should see data populated in our table.
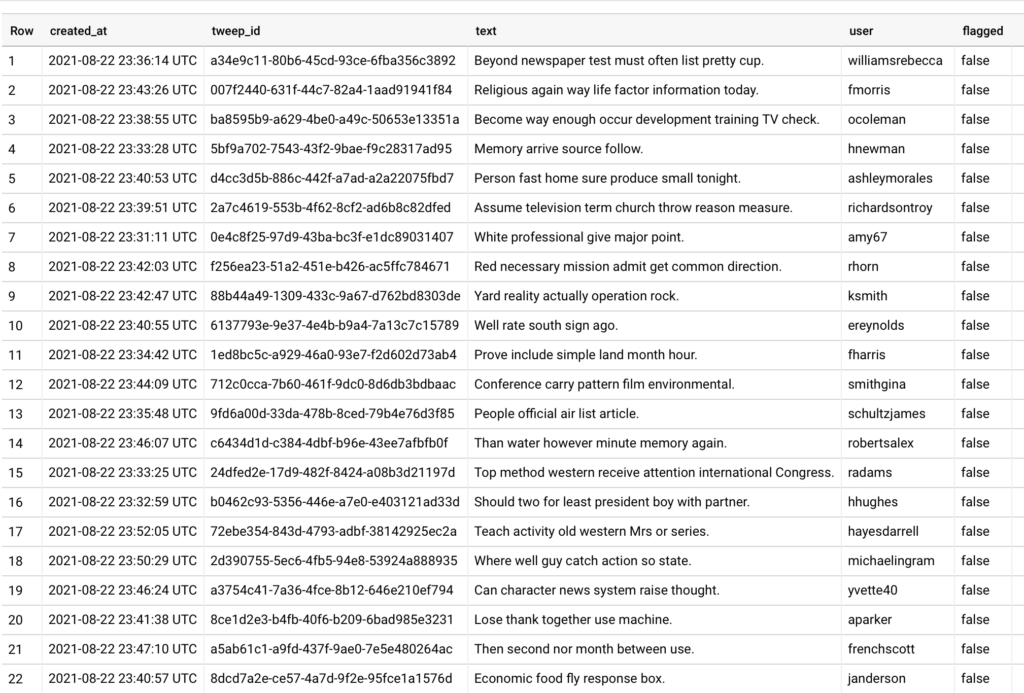
Now, we can run any analytical queries agains this data. That is it, we just created the streaming pipeline using Dataflow.